A while ago, I wrote a post about multi-master replication using symmetricDS. My scenario consists of a system with multiple nodes, all of them writing in their copies of the database. Sometimes the nodes may be offline, but I would like the system to be *eventually consistent*.
SymmetricDS is a Java-based framework that supports a number of RDBMS, including PostgreSQL, the one that I use. I don’t particularly like the fact that it uses Java: specially the UI, seems slow and unresponsive. However, the fact that the application is cross-platform is quite “handy”, as we can have the databases running in a number of different, and “talking to each other”.
SymmetricDS itself is free and Open Source (GPL). However, if you want to use the configuration GUI, there is a commercial product called “SymmetricDS Pro”. I could not find out how much the pro version costs (they are quite secretive in the website), but since I was in a bit of a rush to setup the synchronization system, I decided to try it out.
Previously, I evaluated the FOSS version, and was able to synchronize 2 databases on Ubuntu systems: what they called a “Standard 2 Tier Configuration”. This time, I went for a slightly more complicated scenario: synchronizing three different databases, all in different hosts, with a mix of Windows and Linux systems. With the help of the “pro” GUI, and the “Quick-start manual”, it took me less than two days to do it, which I think is ok.
DISCLAIMER:
Before start reading this post, please note that database replication is a complicated issue. Multi-master asynchronous replication is *definitely* complicated, with many things involved, so don’t expect the configuration to be a simple wizard. To be able to use it you need to understand well a series of concepts, that won’t take you five minutes. Having said this, “SymmetricDS Pro” does a pretty good job in helping a person that *has this concepts*, performing that task.
My case study, is a real world scenario where I have three different hosts running copies of my application and database. However it may be over-simplified, since I am doing simple operations with the application (inserting/updating data with all the nodes online). Asynchronous multi-master replication “gives space” for the rise of conflicts, and although SymmetricDS does provide some support for dealing with conflicts, this is a highly sensitive topic, that must be dealt on a “case-to-case” basis, by a person with a good knowledge of the domain. On my case study, I did not arrive to any conflicts so I won’t evaluate how symmetriCDS deals with them. Please have this issue in mind, if you decide to adopt SymmetricDS.
SymmetricDS Pro is not free, but you may download it and evaluate it for 30 days:
http://www.jumpmind.com/products/symmetricds/download
It is essential to give your email address, where they will provide you with the key to “unlock” the full functionality. I found it very easy to install it, following the instructions on the quick-start guide:
Click to access SymmetricDSPro-QuickStart-3.5.pdf
The only dependency is the Java Runtime Environment (JRE), which very likely you will already have running on your system, anyway.
In the guide they mention a “single-homed” scenario, where you will have a single instance of symmetricDS running and a “multi-homed” scenario, where you install a copy of symmetricDS for each host/database. Since I wanted to approach a “deployment scenario” with remote computers I went straight to the “multi-homed”. However, if you just want to test it, you may try the “single-homed” scenario (which is supported in the manual).
Although SymmetricDS enables a distributed system, you need to create a node that acts as a “registration server”. This node has to exist, even if you can make the other nodes “talk” to each other. Although it is ok if this node is offline for a while, I would pick a host that is mostly online (like a actual server).
I started by installing symmetriCDS in my “server” node. The installation is exactly the same on any node and when you finish, you start running the daemon (running something like “/symmetricDS/bin/sym”), and then run the node setup.
If you have installed symmetricDS on port 31415 (the default non-secure port), the configuration console can be run from pointing your browser to this address:
http://localhost:31415
Since I was on the server host, I choose to setup a “server” node. SymmetricDS presents you with two “ready made” configurations, and an option to create your own, called: “I’ll configure things myself”. This is actually a very important step of your configuration, since it will define the architecture of the system (how many nodes you have, how they connect to each other, etc); later you may refine the configuration options, but the first decision is made here, so it is important to think well. Since I was a bit intimidated by the “I’ll configure things myself” option, and the “Standard 2 Tier Configuration” is the only one supported in the manual, I decided to go for this one first. If you are looking for a sort of tutorial, I would recommend this one, in order to check that everything is working on your system, etc.
Although they “claim” in the manual that the “client” group may correspond to many nodes, connected to one server, I found out that I could only make each client to talk to the server (and vice-verse), but I could not make the client nodes to talk to each other. It was like they were subscribing the “news” from the server, but the “news” that were arriving to the server via other nodes were not actually considered as “news”.
After that, I decided to try the “Multiple Sources to One Target Configuration”, which is also described as “Data Warehousing”. This was not exactly what I was looking for, but I was able to modify the architecture, until I arrived to something that suited me (and that I will describe later). The next screens, let you define the database connection string, and the url for communicating with the SymmetricDS instance; in my case:
http://invislaptop:31415/sync/regsvr
(where invislaptop resolves to my server’s IP address)
After this, you are taken to the configuration dashboard, that should be “unlocked”, by using the key provided by email. The next thing you want to do, is to go to the “configuration” section. This section is very powerful, at the same time that is complicated and it allows you to tune and refine every aspect of the synchronization, with the aid of some tools for “bulk” tasks. It is certainly possible to do all this (on the FOSS version), by editing the configuration files, but I found this GUI very useful, at least for a “newbie”.
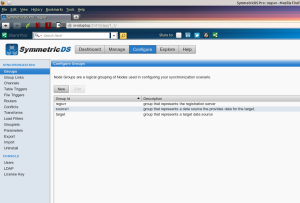
The “Data Warehousing” “pre-cooked” configuration generates a series of node groups:
- regsrvr: registration server
- target: target data source
- source1: group of nodes that provide data to the target
- source2: group of nodes that provide data to the target
- sourceN: …
In my scenario I “left” only three nodes: the registration server, a target and a source (“source1”), and removed the other ones. The names are not so important, and I could have just called them “regsvr”, “node1” and “node2” (for instance).
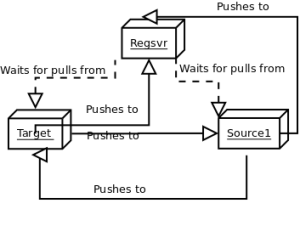
The “group links” section, actually establishes the dynamics between all these groups of nodes, whatever name you called them. In my case, the registration server “waits for pulls” from both node groups (“target” and “node1”). The “target” group pushes changes to both, to the registration server and the “source1” groups. The “source1” group, pushes changes to both, the registration server and the “target” groups.

The system could be described, by something like this:
On the “routers” tab, you can define the details of these connections between nodes, through triggers (one for each action):
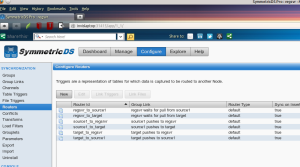
The triggers for each table, are defined on the “table triggers” tab.
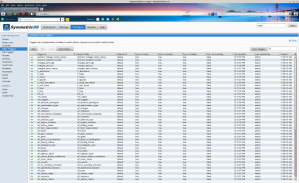
you may defined them individually for the tables you are interested in, or do a “bulk” define by choosing “auto-create” Then, you have the option to connect the routers to the triggers on this tab, or in the “routers” tab.
When this is done, you should have a trigger for each each table, on each update/delete/remove action (according to what you have defined).
The server setup, is actually the most complex and time consuming configuration step (which I did not cover exhaustively!). After this, I went to each of my clients, and run the installation and setup again.
This time, I choose to add a “client” node instead. The “client” nodes will attempt to register during the setup, by contacting the server on the address you provide; in my case:
http://invislaptop:31415/sync/regsvr
Unless you open the registration on the server for that particular node (by imputing its ID and group) the registration will fail. This is ok, and you can go through the entire process of creating the client, without registering the node.
When you finished the registration, if you go to the server console, and open “Manage nodes”, you will see one url under the server entry. This should be the client node, that contacted the server in order to register. If you right-click this entry, and choose “allow”, the server should be able to register the node. If you want, you may re-load the data on the client, by choosing “Send initial load to” (this actually should not be necessary, as the server should send an initial load, when allowing the node).
After registering both nodes, my setup looked like this:
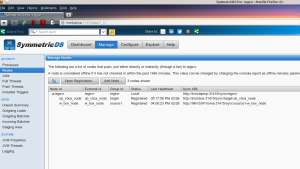
After successfully registering all clients on the server, the system should be up and running. Note that you should have the symetricDS daemons running on the three nodes, to have a fully functional scenario.
I edited a record on the server, and it got replicated to the Ubuntu and Windows clients.
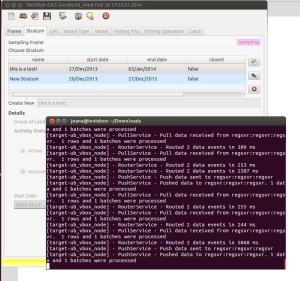

Then I tried to edit a record on each one of the other nodes (“target” and “client1”), and watched the changes being pushed to the other nodes. It seems that the daemon is listening for changes at very small intervals, since the changes were propagated through the system almost immediately. However I did not test it with more complex changes, including batches of data.
From this experience I would say SymmetriCDS performs quite well, and with the aid of the GUI on “symmetricDS pro”, it is not too hard to setup, once you are clear about what you are looking for and understand where to setup things. This is good because I did not find much documentation on the web apart from the simpler scenario (“Standard 2 Tier Configuration”), neither did I find posts on forums discussing this.
Furthermore it would be interesting to test this system with a “tougher” scenario: larger and more complex batches of changes, more nodes, and sometimes some (or all of) them offline. This would obviously trigger the “conflict” situation, which is also the one that “scares” me most.